
I’ve been a loyal follower of Data Eng Weekly newsletter (formerly Hadoop Weekly) for the past 6 years, the newsletter is a great source for everything related to Big data and data engineering in general with a wide selection of technical articles along with product announcements and industry news.
For this year’s holidays side project I decided to analyze Data Eng’s archives, that go back to January 2013, to try to analyze Big data trends and changes over the past 6 years.
So I crawled and cleaned over 290 weekly issues (well python did !), I kept articles’ snippets from the technical, news and releases sections only. Next, I ran some basic natural language processing followed by some basic filtering to produce keywords mentions and all of the plots that follow.
Major trends over the last seven years
Let’s start with the major trends over the last seven years, here I’m calculating the monthly rolling mean of the number of mentions of specific keywords and plotting them together on the same graph. The following plots illustrate at what approximate time frames technologies become more popular (as a result of more reporting about these technologies) when compared together.
Hadoop vs. Spark
Observations : We see the steady decline of Hadoop since 2013 and the moment Spark took over Hadoop (especially MapReduce).
Hadoop vs. Kafka
Observations : The rise of Kafka as the main building block in all Big data stacks.
Hadoop vs. Kubernetes
Observations : An interesting observation is the rise of Kubernestes, even though the Data Eng Weekly is not a Devops newsletter, is a witness to the overall hype around Kubernetes in all domains starting from beginning of 2017.
Yearly top keywords
Here I’m simply plotting the top 10 keywords by total number of mentions in a give year.
2013 : Hadoop’s golden year !
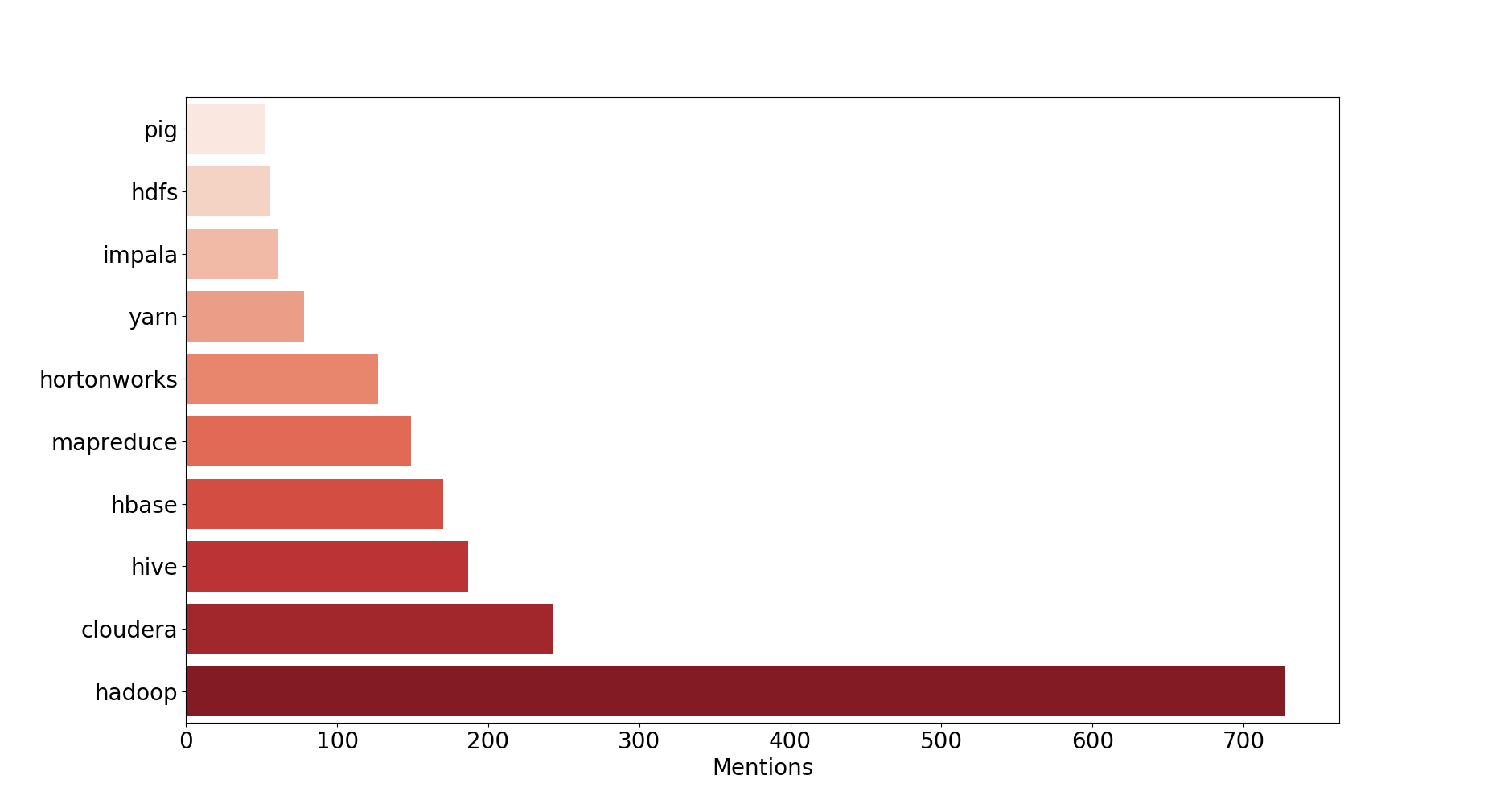
Observations : All of the original Hadoop projects are here : HDFS, YARN, MR, PIG, … With the 2 major distributions CDH & HDP and nothing else !
2014 : The rise of Spark !
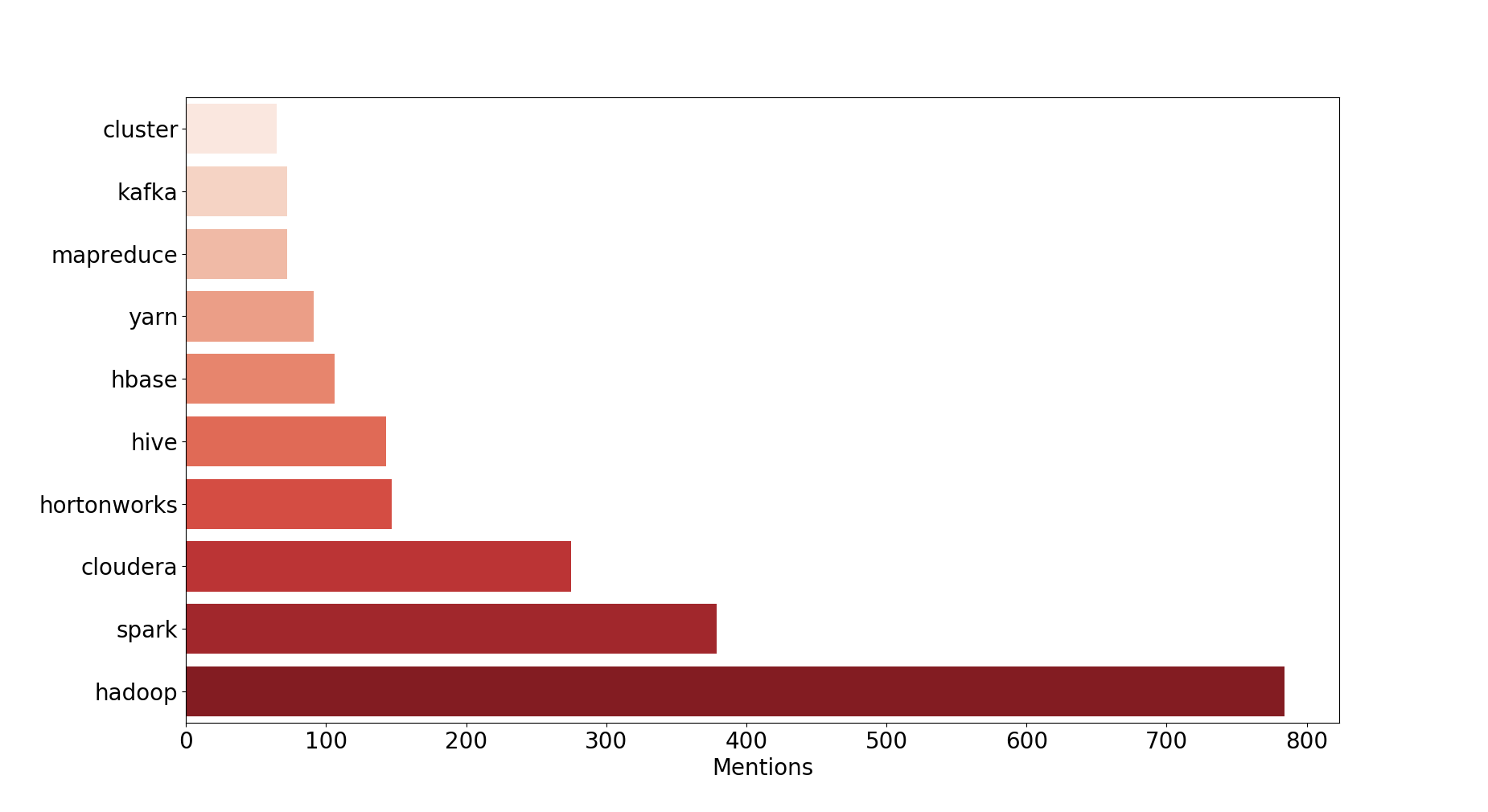
Observations : Hadoop in general continued its dominance but Spark made its debut with its first version this year was the hottest topic of 2014, e also got the first glimpse of Kafka !
2015 : Here comes Kafka !
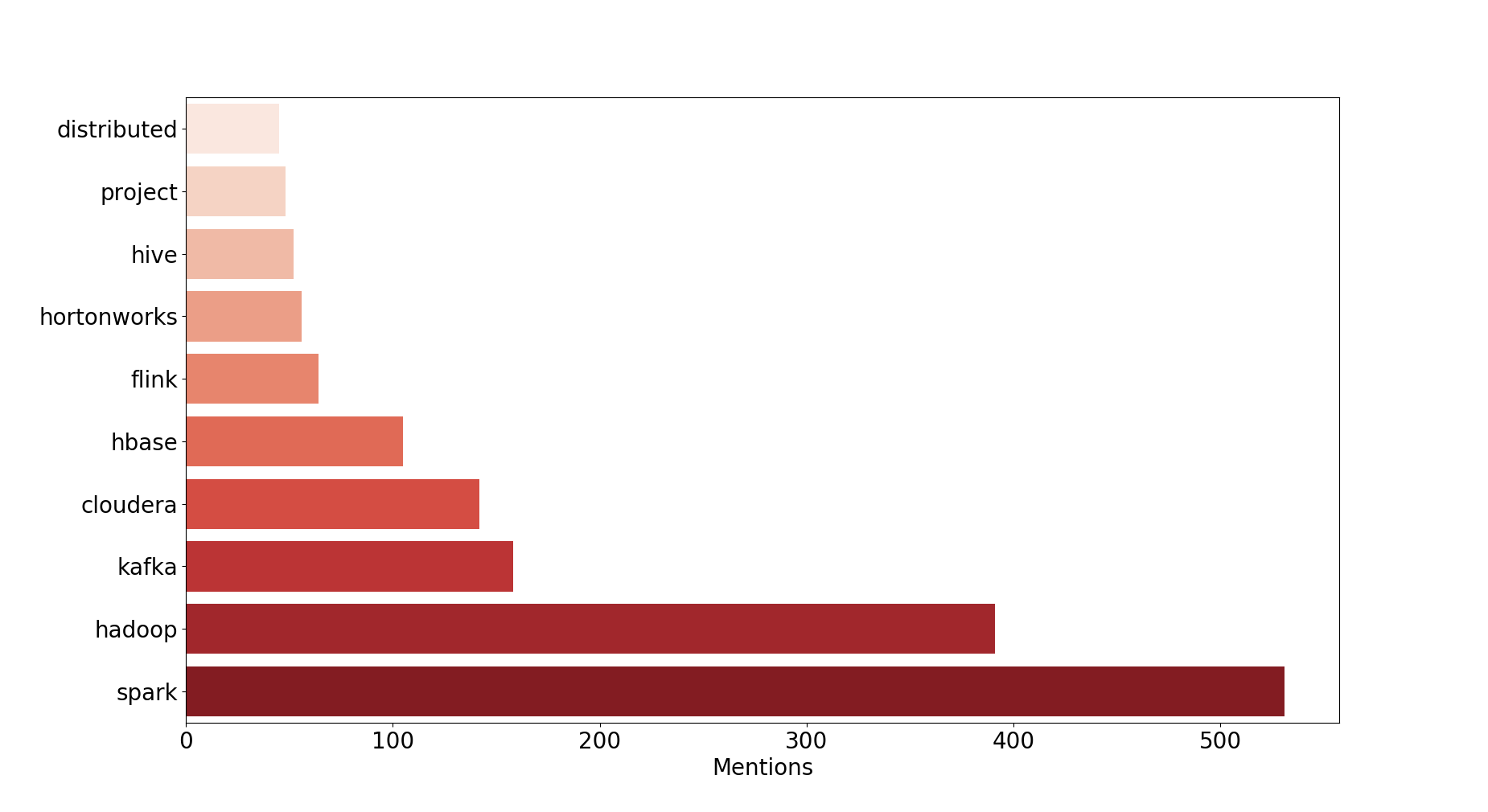
Observations : Spark takes ever the first spot from Hadoop and Kafka making it to the top 3. Most of the old regime projects (HDFS, YARN, MR, PIG, …) didn’t make to the top 10.
2016 : Streaming is on fire !
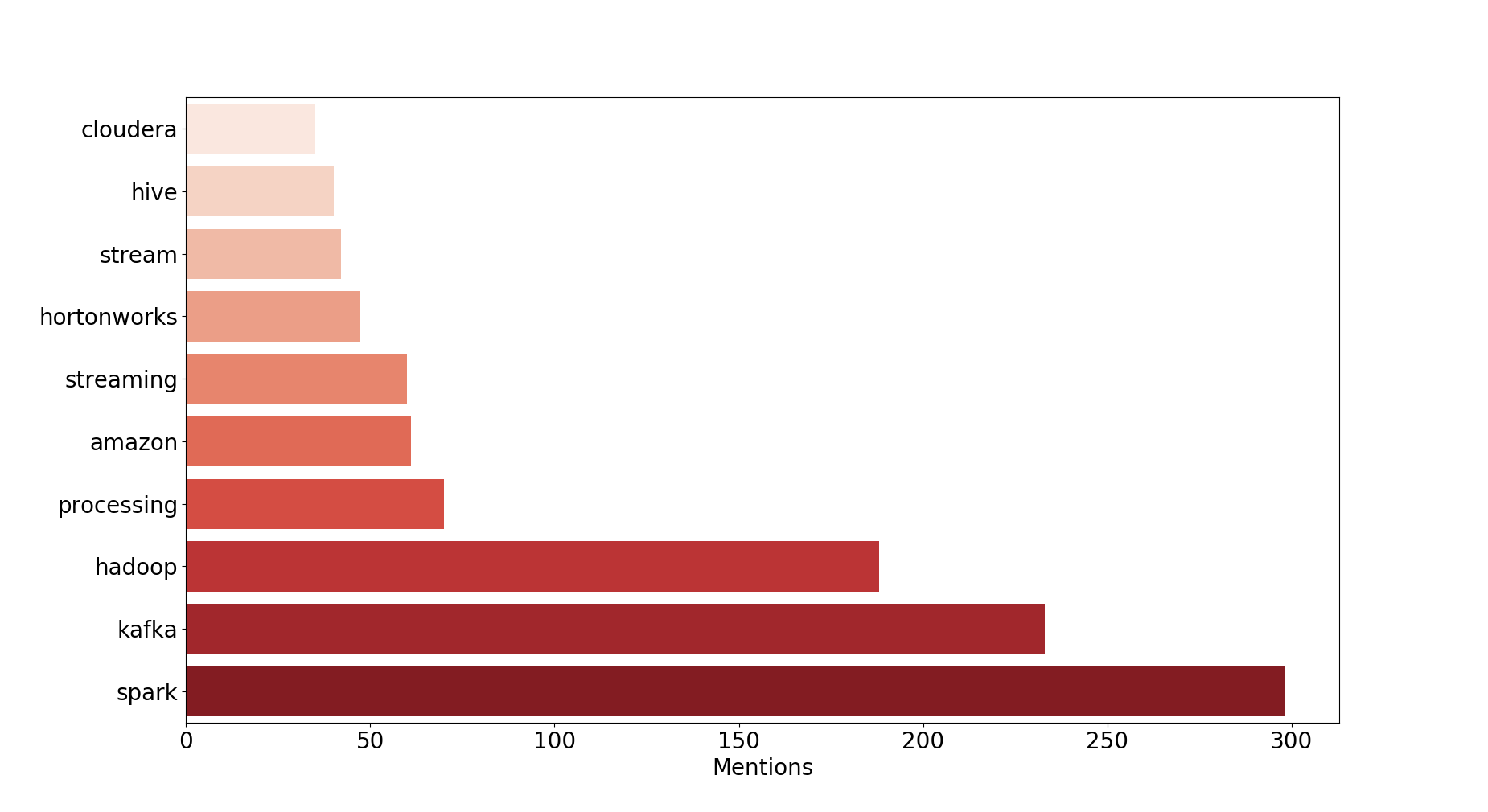
Observations : 2016 was the streaming year, Kafka took the second place from Hadoop with Spark (streaming) continuing its dominance.
2017 : Stream everything !
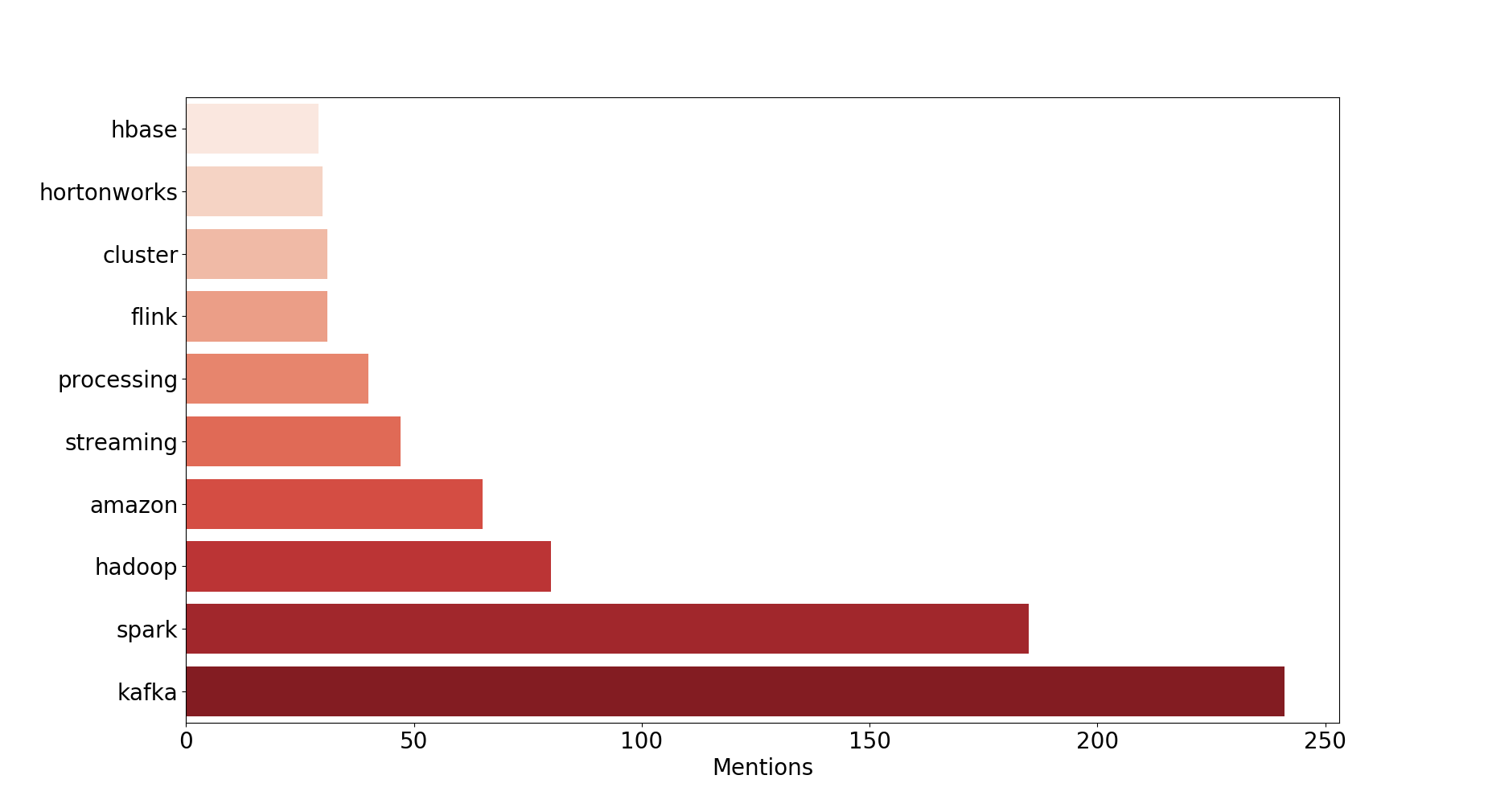
Observations : The same lineup as 2016 with some Flink thrown in.
2018 : Back to basics !
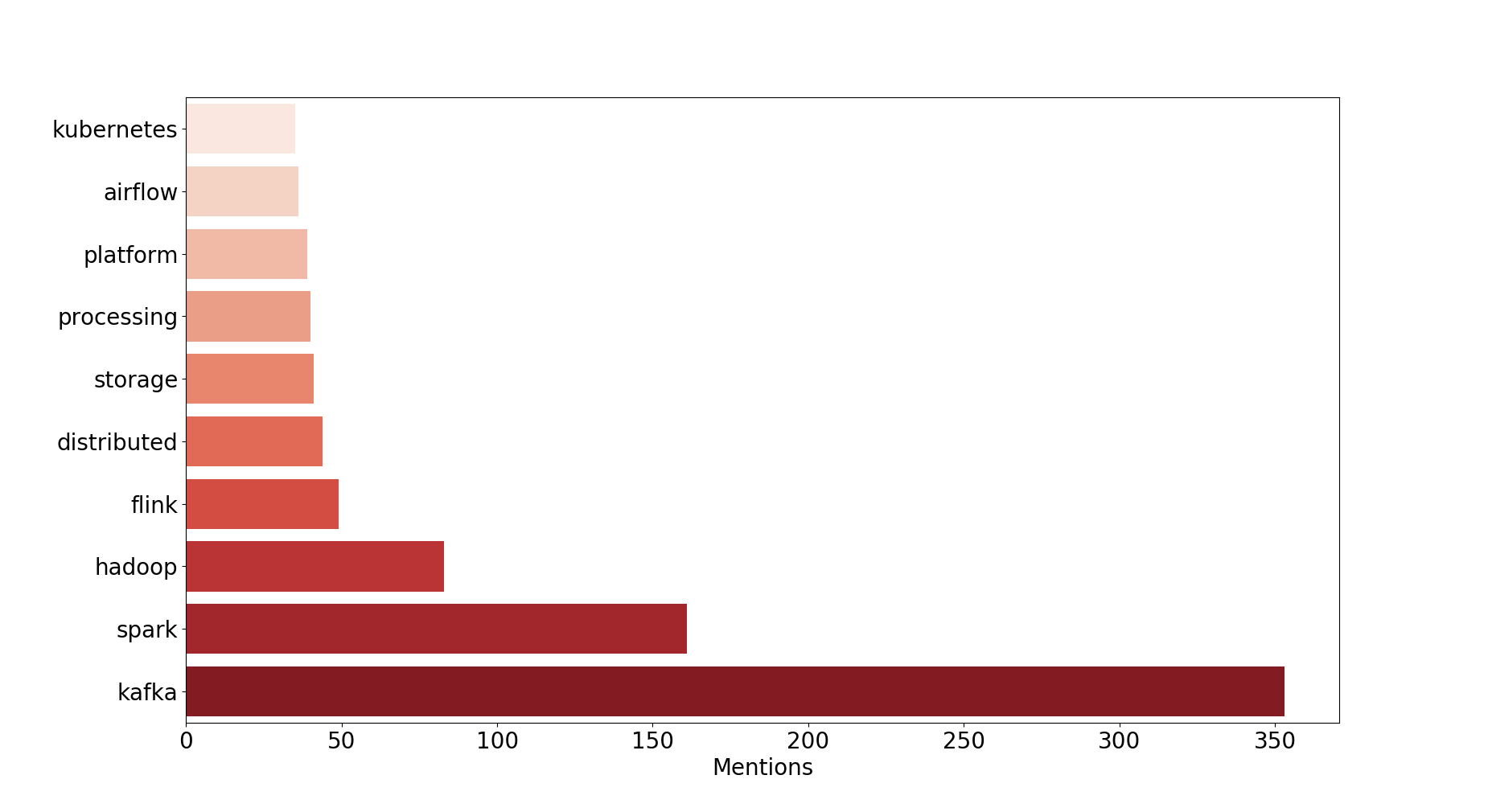
Observations : Kubernetes makes its debut and we’re back to basics trying to figure out the how to manages (K8S), schedule (airflow) and run (Spark, Kafka, Storage, …) our streams.
2019 : …
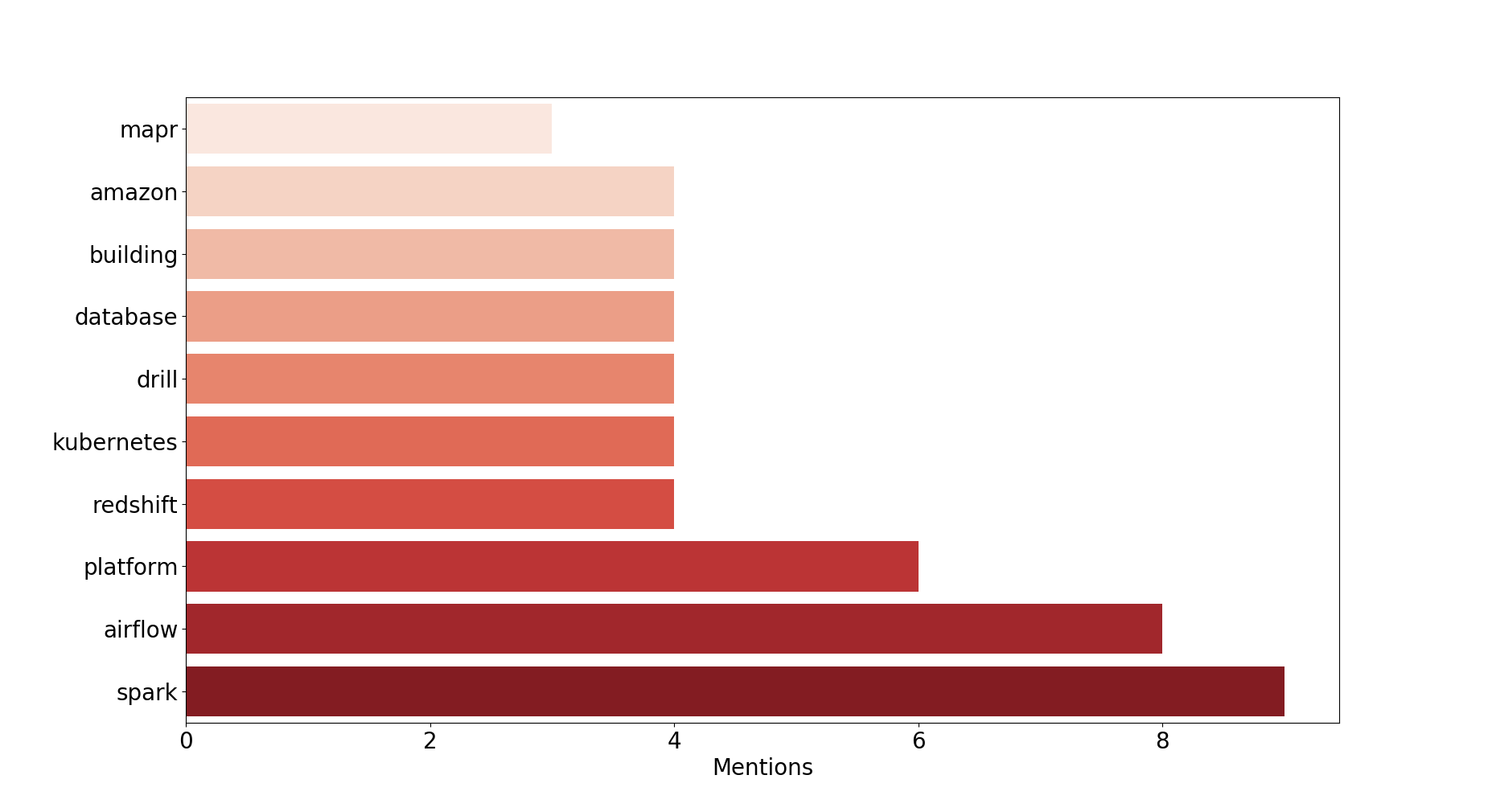
Observations : It’s still too early to make any conclusions about 2019, but it looks like the year where K8s & co. go prod. mainstream !
Code and dataset
I’m working on cleaning up the code so that you can generate the dataset by yourself. I’ll also be posting the NLP python snippets along with Bokeh & Seaborn plot generating snippets, so stay tuned.
Update 17/02/2019
The blog post got translated to chinese by Zhenwen Xu, so if you’re more comfortable with chinese you can read it here : http://helight.info/2019-02-13/1187